DRF Serializers: 데이터 포맷의 마법사 🧙♂️
Django REST Framework(DRF)의 시리얼라이저(Serializer)는 REST API에서 데이터를 주고받기 쉽게 변환해주는 만능 해결사입니다.
"데이터가 뭐라고? 난 그냥 Python 객체를 보내고 싶을 뿐인데!"DRF: "걱정 마세요, JSON으로 바꿔 드릴게요!"😎
📌 DRF 시리얼라이저의 역할
- 서로 다른 환경에서도 데이터를 원활히 통신할 수 있도록 변환합니다.
- 복잡한 데이터를 JSON, XML 등 친숙한 포맷으로 변신시킵니다.
- Django에서 사용하는 파이썬 객체나 queryset을 REST API에서 사용할 수 있도록 변환합니다.
- 보너스로 데이터 유효성 검사 같은 기능도 제공하죠! 🚀
1. 왜 Serializers를 써야 할까?
Django의 강력한 ORM을 활용하여 queryset을 다루고 CRUD 기능이 필요할 때, HTTP 요청(method)과 매끄럽게 연결되는 View가 필요합니다.
예를 들면? GET, POST, PATCH, PUT, DELETE 같은 HTTP 메서드 말이죠!
"서버야, 이 데이터 좀 JSON으로 만들어줘!" Serializer: "그쵸, 제가 없으면 힘들죠?" 😏
기본 Serializer
serializers.Serializer
- 가장 기본적인 serializers.Serializer부터 살펴봅시다. model 예시는 아래 Profile라는 model을 가지고 하겠다.
class ProfileSerializer(serializers.Serializer):
id = serializers.CharField(help_text='종목코드')
created = serializers.DateTimeField()
platform = serializers.CharField(help_text='유입 플랫폼')
gender = serializers.SerializerMethodField(read_only=True)
# 모델과 시리얼라이져
queryset = User.objects.get(id="712c43a4-e426-4aa5-b1f9-4b5c8d90628e")
# 시리얼라이저를 담았을때, 콘솔에서 확인하면 아래와 같이 나오게 된다.
UserSerializer(queryset)
UserSerializer(<Product: User object (712c43a4-e426-4aa5-b1f9-4b5c8d90628e)>):
id = CharField()
created = DateTimeField()
platform = CharField()
gender = SerializerMethodField()
serializer = UserSerializer(queryset)
serializer.data
Out[3]: {'id': '712c43a4-e426-4aa5-b1f9-4b5c8d90628e', 'created': '2025-01-20T18:03:39.570582+09:00', 'platform': '무신사'}
# Dict -> 시리얼라이져
request = {
"id": "712c43a4-e426-4aa5-b1f9-4b5c8d90628e",
"platform": "쿠팡",
"gender": "male"
}
UserSerializer(request)
# validate 에러 발생
...
raise type(exc)(msg)
KeyError: "Got KeyError when attempting to get a value for field `created` on serializer `UserSerializer`.\nThe serializer field might be named incorrectly and not match any attribute or key on the `dict` instance.\nOriginal exception text was: 'created'."
ModelSerializer: 귀찮음을 없애주는 구세주!
serializers.Serializer를 쓰다 보면 이런 생각이 들 수 있습니다.
"아니, 모델에 이미 필드가 다 적혀 있는데,똑같이 또 써야 한다고? 이게 맞아?" 🤯
맞아요, serializers.Serializer는 ORM을 위한 게 아니었어요! 하지만 걱정 마세요. Django 모델을 위한 진짜 Serializer가 있습니다.
바로 ModelSerializer입니다! 🚀 기존의 UserSerializer를 아주 간단하게 바꿀 수 있죠.
보시죠! 👇
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = "__all__"
위 코드에서는 모든 필드를 response로 포함 하도록 설정했어요. 하지만, 정말 모든 필드를 다 보내야 할까요? 🤔
🛑 "이건 너무 과한데?"
만약 일부 필드를 제외하고 싶다면 exclude 옵션을 사용하면 됩니다.
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
exclude = ("id",) # 'id' 필드는 응답에서 제외!
이렇게 하면 id 필드는 response에 포함되지 않아요. 깔끔하죠? 😎
🎯 "필요한 것만 딱 줄 수 없을까?"
당연하죠! 원하는 필드만 골라서 response에 포함시키고 싶다면?
class UserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ['id', 'user', 'created'] # 필요한 것만 선택!이렇게 하면 id, user, created 필드만 딱 반환됩니다. 선택과 집중! 🎯 이제 어떤 방식으로든 원하는 데이터만 response에 포함시킬 수 있어요!
SerializerMethodField: 원하는 데이터 가공하기
때로는 모델에 있는 필드 그대로가 아니라, 조금 더 가공된 데이터를 API 응답에 포함하고 싶을 때가 있죠!
예를 들어, UserSerializer에서 gender(성별)을 숫자로 저장하는 대신 "남성" 또는 "여성"으로 변환해서 반환하고 싶다면? 바로 SerializerMethodField를 사용하면 됩니다! 🎩✨
class UserSerializer(serializers.ModelSerializer):
gender = serializers.SerializerMethodField(read_only=True) # 추가 필드 정의
class Meta:
model = User
fields = "__all__"
def get_gender(self, obj):
if obj.gender_code is not None:
return "남성" if obj.gender_code % 2 else "여성"
return obj.gender_code # None이면 그대로 반환
🤔 어떻게 동작하나요?
- gender = serializers.SerializerMethodField(read_only=True)
- 모델에는 없지만, API 응답에는 추가할 필드를 선언합니다.
- get_gender(self, obj)
- get_필드명(self, obj) 형식으로 메서드를 작성해야 합니다!
- 여기서 obj.gender_code 값을 활용해 성별을 판별합니다.
- 만약 gender_code가 홀수면 "남성", 짝수면 "여성"으로 변환됩니다.
🎯 SerializerMethodField 언제 사용하면 좋을까?
- 모델 필드를 그대로 쓰기엔 조금 가공이 필요할 때
- 특정 필드 값에 따라 새로운 값을 만들어야 할 때
- 계산된 값, 외부 API 데이터 등 추가 정보가 필요할 때
Nested Serializers: 다중 시리얼라이저 활용하기
📌 1:1 관계 (OneToOneField)에서 Nested Serializer 활용하기
때로는 하나의 모델만 직렬화하는 것으로는 부족하죠. 예를 들어, User 모델이 있고, 이와 1:1 관계를 가지는 UserProfile 모델이 있다면, 이제 두 모델의 데이터를 한 방에 직렬화하고 싶을 거예요!
class UserProfile(models.Model):
user = models.OneToOneField(User, on_delete=models.CASCADE, related_name='profile', verbose_name='사용자')
nickname = models.CharField(max_length=60,null=True,blank=True, verbose_name='사용자 닉네임')
class User(models.Model):
user_id = models.CharField()
class UserProfileThumbnailSerializer(serializers.ModelSerializer):
""" 사용자 프로필 정보를 직렬화하는 Serializer """
class Meta:
model = UserProfile
fields = ['nickname']
class UserThumbnailSerializer(serializers.ModelSerializer):
""" Nested Serializer를 활용한 User Serializer """
profile = UserProfileThumbnailSerializer(label='프로필 정보', required=False) # 여기서 중첩!
class Meta:
model = get_user_model()
fields = ['id', 'profile']
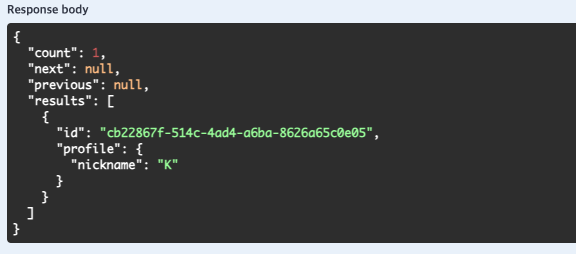
👆 이처럼 profile 안에 nickname이 포함된 형태로 응답을 받을 수 있습니다.
여기서 핵심은?
- UserProfileThumbnailSerializer에서 nickname만 반환하도록 설정
- UserThumbnailSerializer에서 profile 필드에 Nested Serializer 적용!
이제 User 데이터를 조회하면 profile 필드가 자동으로 UserProfile의 데이터를 포함해서 반환합니다! 😍
🎯 Nested Serializer 언제 사용하면 좋을까?
✔️ 1:1 관계 또는 1:N 관계에서 연관 데이터를 함께 직렬화하고 싶을 때
✔️ 각각의 모델을 따로 직렬화할 필요 없이, 한 방에 데이터를 받고 싶을 때
✔️ API 응답을 더 직관적으로 만들고 싶을 때
🚀 DRF의 기본 create는 단일 객체만 다룬다?
Django REST Framework(DRF)에서 create()는 기본적으로 한 개의 모델 인스턴스만 생성할 수 있어요.
하지만 가끔은 여러 개의 데이터를 한 번에 만들고 싶을 때가 있죠! 🤔
"이거 한 개씩 만들다가는 손가락 나가겠는데?🫠 여러 개를 한 번에 만들 방법 없을까?"
그럴 때 필요한 게 바로 "Bulk Create"! 하지만...
"이걸 Serializer에서 처리하는 게 좋을까?🤔"
아니요! 사실 bulk create는 Serializer 레벨에서 처리하는 것보다는View 레벨에서 create_many 로직을 활용하는 게 더 좋아요! 😎
def create(self, request, *args, **kwargs):
kwargs["many"] = isinstance(request.data, list) # 데이터가 리스트인지 확인!
serializer = self.get_serializer(data=request.data, **kwargs)
serializer.is_valid(raise_exception=True)
serializer.save() # 여러 개 저장 가능!
return Response(status=status.HTTP_201_CREATED)🔥 이 코드에서 중요한 포인트!
kwargs["many"] = isinstance(request.data, list)
- 만약 요청 데이터(request.data)가 리스트 형식이면 **many=True**로 설정!
- 이렇게 하면 Serializer가 한 개가 아니라 여러 개의 객체를 처리할 준비를 하게 됨!
serializer.is_valid(raise_exception=True)
- 데이터를 검증해서 문제가 있으면 예외를 던짐! (검증 오류 방지)
serializer.save()
- **many=True**인 경우에도 알아서 여러 개의 객체를 저장! 🚀
return Response(status=status.HTTP_201_CREATED)
- 성공적으로 저장되었음을 응답! (클라이언트가 알기 쉽게)
⚡ List Serializer vs. bulk_create(): 성능 차이 완벽 비교
DRF의 create()는 기본적으로 한 번에 하나의 객체만 저장해요. 즉, 100개의 데이터를 저장해야 한다면?
for item in data:
Model.objects.create(**item) # 데이터 하나씩 생성!"하나 저장... 둘 저장... 셋 저장... 😩"
이렇게 하면 100번의 INSERT 쿼리가 실행됩니다. DB가 계속 바쁘게 움직여야 하고, 성능이 좋지 않아요.
Model.objects.bulk_create(
[Model(**item) for item in data]
)
단 1번의 대형 INSERT 쿼리로 100개의 데이터를 한꺼번에 저장할 수 있어요! 즉, 쿼리 실행 횟수가 줄어들어 성능이 훨씬 좋아집니다.
성능 비교: bulk_create() vs create()
방법 퀴리 실행 횟수 성능 데이터 무결성
| 방법 | 퀴리 실행 횟수 | 성능 | 데이터 무결성 |
| 기본 create() | 100개의 데이터 → INSERT 100번 | 느림🐢 | 개별 객체 생성 가능 |
| bulk_create() | 100개의 데이터 → INSERT 1번 | 빠름🚀 | 개별 유효성 검사 x |
그럼 언제 bulk_create()를 써야 할까?
✔ 대량의 데이터를 한꺼번에 저장해야 할 때 (100개 이상이면 **bulk_create()**가 훨씬 빠름!)
✔ DB 부담을 줄이고 싶을 때
✔ 객체 생성 후 추가적인 후처리(save 호출 등)가 필요 없을 때
하지만, bulk_create()는 개별 객체의 save() 메서드를 호출하지 않으므로
- 후처리(예: 신호 보내기, 추가 데이터 처리 등)가 필요하다면 일반 create()를 고려해야 합니다!
bulk_create() + View 레벨에서 처리
앞서 설명한 create() 메서드에서 many=True를 활용하면서,
bulk_create()를 적용하면 최적의 성능을 낼 수 있어요!
def create(self, request, *args, **kwargs):
data = request.data
if isinstance(data, list): # 여러 개의 데이터인지 확인
instances = [Model(**item) for item in data]
Model.objects.bulk_create(instances) # 한 방에 저장!
return Response(status=status.HTTP_201_CREATED)
return super().create(request, *args, **kwargs) # 기본 create 실행
'프로그래밍 > Django' 카테고리의 다른 글
| 🐜 Locust: 부하 테스트의 끝판왕! (0) | 2025.02.27 |
|---|---|
| ElastiCache(Redis) Redis Insight EC2를 활용하여 접근하기 (0) | 2025.02.26 |
| Django ORM 최적화: GenericForeignKey를 활용한 데이터 모델링 (0) | 2025.02.19 |
| View가 깔끔해지는 Django 필터링 전략! get_queryset() vs filter_queryset() (0) | 2025.02.18 |
| Django 대량의 list 요청시 Cursor-based Pagination (0) | 2025.02.18 |


