해당 내용의 원문은 [링크] 이곳에서 발췌해왔습니다😀
이전에 글에서 언급했던 N+1문제를 해결하는 방법에 대해서 적으려고한다.
N+1문제에 대해선 아래 링크에 적어두었고, 해당 링크 하단쯤에 내용이 있으니 참조하면 좋을것같다.
[Django][Python]QuerySet을 통해 알아보는 ORM의 특징
해당 정보는 Pycon자료를 통해 만들었습니다. 참고자료는 아래와 같습니다 [링크1], [링크2] ORM이란? ORM 설명 Object Relational Mapping, ORM은 객체 지향적인 방법으로 데이터를 쉽게 조작할 수 있게 해준
dentuniverse.tistory.com
위의 링크에서 내용을 읽었다는 전제하에 내용을 추가로 적으려고한다.
아래는 예제 코드이다.
아래의 코드를 보면 위 링크에서 언급한 N+1문제가 발생하게 된다.
users를 for문으로 돌리기 시작하면서 처음 선언했던 User.objects.all()이 발생하여, 모든 정보를 가져오고, 그 이후에 우리가 필요한 Userinfo정보를 다시 쿼리문을 통해서 가져오게된다.
이 경우에 user정보가 100개라면, 쿼리문을 100번 호출하게 되는 비효율적인 움직임이 발생하게 되는것이다.
(* 참고로 여기서 userinfo는 user와 1:1관계로 묶여있다.)
# Model.py
class UserInfo(models.Model):
tel_num = models.CharField(max_length=128, null=True)
class User(AbstractUser):
userinfo = models.OneToOneField('orm_practice_app.UserInfo', on_delete=models.CASCADE, null=False)
aab = models.ForeignKey("AAB", on_delete=models.CASCADE, null=True)# N+1 Problem 예제
def i_am_function_view3_1(request: WSGIRequest):
# User를 선언하는 시점에는 SQL이 호출되지 않음
users: QuerySet = User.objects.all()
# 개발자 관점에는 각user의 모든 userinfo가 필요한 것을 알지만 QuerySet은 그걸 모른다.
for user in users:
# QuerySet입장에서 user의 userinfo 가 필요한 시점은 여기다.
# 따라서 userinfo를 알기위해 SQL을 for문이 돌때마다(N번) 호출한다.
user.userinfo
user_list: List[User] = list(users)
# 직렬화 로직
user_list_dict: List[Dict[str, Any]] = [
model_to_dict(user)
for user in user_list
]
user_list_json_array: str = json.dumps(user_list_dict, indent=1, cls=DjangoJSONEncoder)
return HttpResponse(content=user_list_json_array, content_type="application/json")
같은 모델안에 있는 데이터를 가지고 오려하면, 이전에 설명했던 캐싱 방식을 통해서 해결할 수 있으나, 다른 모델과의 관계를 갖고 있을 경우에는 곤란할 때가 있다.
이 문제를 해결하기 위해서 Eager Loading(즉시 호출)의 방식으로 해결할 수 있다.
Eager Loading에는 2가지 메소드를 제공한다.
1. select_related : 원래의 쿼리에 JOIN을 통해서 즉시 로딩하는 방식을 말하는데,
foreign-key, one-to-one처럼
single valued relationships에서만 사용이 가능하며 보통 정참조할 때 많이 사용된다.
(SQL의 JOIN을 사용하는 방식)
2. prefetch_related : 추가 쿼리를 수행해서 데이터를 즉시 로딩하는 방식을 말하는데,
foreign-key, one-to-one뿐만 아니라 many-to-many, many-to-one 등
모든 relationships에서 사용 가능하다.
(SQL의 WHERE ... IN 구문을 사용하는 방식)
다음은 나의 예제이다.
일단 기존의 방식인 objects.all()을 활용하여 모델의 모든 정보를 가져오고, 그 중에서 Cafe모델이 참조하고 있는 user모델을 가져오게 되는데, 아래와 같이 내 DB에 담겨있는 데이터만큼 퀴리를 호출하게 된다.
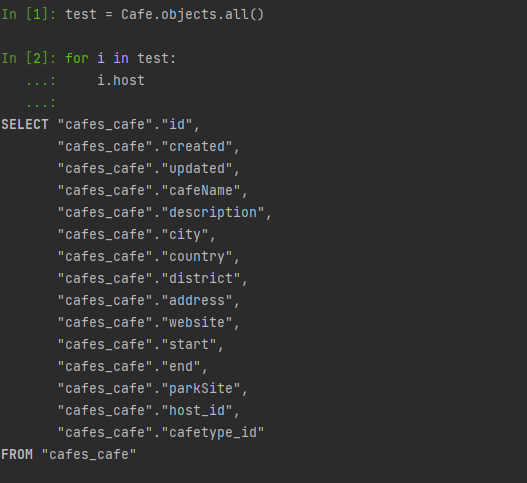
반면에 select_related를 활용하게 되면? 아래와 같이 host를 한번만 호출하여 데이터를 가져올 수 있다.
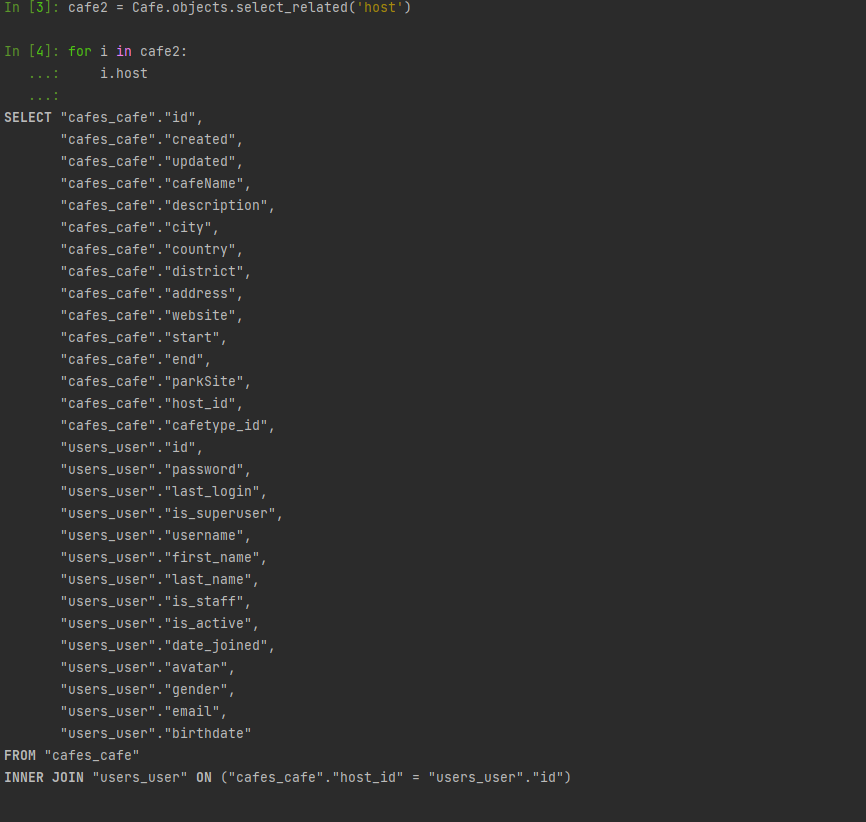
마치며
ORM의 N+1의 문제에 대한 이해와 select_related, prefetch_related 시에 먼저 내가 원하는 데이터 구조를 생각하고, 차근차근 짜는 습관을 들이면 같은 데이터 추출이라도, 엄청난 성능 향상을 기대할 수 있을것 같다. 이상!
ORM쪽 정리는 계속 할 것 같다..ㅎ
'프로그래밍 > Django' 카테고리의 다른 글
| [Django] 멀티 DB 라우터설정 및 연동하기 (0) | 2022.05.11 |
|---|---|
| [Django][에러노트]raise ValueError, "No frame marked with %s." % fname (0) | 2022.05.07 |
| [Django][Python]QuerySet 캐싱을 통해 문제 해결하기 (0) | 2022.04.06 |
| [Django][Python]QuerySet을 통해 알아보는 ORM의 특징 (0) | 2022.04.06 |
| [Django][Python]Silk라이브러리를 활용한 Django 서버부하 프로파일링 설치 (0) | 2022.04.06 |



