개요
Image를 사용하여 data를 만들고 머신러닝을 학습시키기 위헤서 다량의 이미지 데이터가 필요해졌다. 알다시피 구글, 네이버 등에서 하나하나 데이터를 저정하는것이 시간이 상당히 오래걸리는 일이기 때문에 Crawling을 통해서 데이터를 수집하게 되었다.
참고로 나는 Beatifulsoup을 사용하지 않고 selenium만 사용해서 코드를 짜봤다..
왜 Beatifulsoup을 사용하지 않은가에 대해서 의문이 있을텐데 내 경우는 아래와 같기 때문이다.
(아래 이미지는 구글을 사용했으나 실질적으로 내가 긁어온 곳은 네이버이다...구글은 내가 한 방식으로는 안되기때문에...추가적으로 코드를 수정해서 구글도 되게끔 수정할 예정이다..)

구글에서 특정 단어를 가지고 입력을 하면 위와 같이 썸네일이 나오게 된다. 여기서 Beatifulsoup를 사용하면 썸네일로만 구성된 html코드가 나오게 되서 이미지를 저장하면 썸네일 이미지만 저장이 된다.
하지만 내가 필요한 이미지는 썸네일 사진(64x64정도..)이 아닌 해상도가 좋은 사진을 원하기 때문에 Beatifulsoup를 사용한 방식으로는 할 수 없다고 판단했다.
즉, 아래와 같이 내가 원하는 이미지는 썸네일을 클릭하여 옆에 나오는 큰 이미지가 필요했고, 클릭을 할 경우에 변경되는 html을 사용해야 했다.
이 부분을 해결하기 위해서 selenium을 사용해서 크롤링하였다.
(selenium에 대한 설명은 Crawling 설정편에 적어두었다. 참고하길 바란다.)

구조
1. webdriver를 통해서 web페이지로 들어간다.
2. web페이지에서 썸네일을 클릭하고, 우측에 나오는 이미지의 src를 긁어온다.
3. 긁어온 이미지를 저장한다.
코드
#!/usr/bin/python
# -*- coding: <encoding name> -*-
from selenium import webdriver
import requests as req
import time
from selenium.webdriver.common.keys import Keys
from urllib.request import urlopen
#브라우저를 크롬으로 만들어주고 인스턴스를 생성해준다.
browser = webdriver.Chrome()
#브라우저를 오픈할 때 시간간격을 준다.
browser.implicitly_wait(3)
count = 0
검색어 = '풍경'
photo_list = []
before_src=""
#개요에서 설명했다시피 google이 아니라 naver에서 긁어왔으며,
#추가적으로 나는 1027x760이상의 고화질의 해상도가 필요해서 아래와 같이 추가적인 옵션이 달려있다.
경로 = "https://search.naver.com/search.naver?where=image§ion=image&query="+검색어+"&res_fr=786432&res_to=100000000&sm=tab_opt&face=0&color=0&ccl=0&nso=so%3Ar%2Ca%3Aall%2Cp%3Aall&datetype=0&startdate=0&enddate=0&start=1"
#해당 경로로 브라우져를 오픈해준다.
browser.get(경로)
time.sleep(1)
#아래 태그의 출처는 사진에서 나오는 출처를 사용한것이다.
#여기서 주의할 점은 find_element가 아니라 elements를 사용해서 아래 span태그의 img_border클래스를
#모두 가져왔다.
photo_list = browser.find_elements_by_tag_name("span.img_border")
for index, img in enumerate(photo_list[0:]):
#위의 큰 이미지를 구하기 위해 위의 태그의 리스트를 하나씩 클릭한다.
img.click()
#한번에 많은 접속을 하여 image를 크롤링하게 되면 naver, google서버에서 우리의 IP를 10~20분
#정도 차단을 하게된다. 때문에 Crawling하는 간격을 주어 IP 차단을 피하도록 장치를 넣어주었다.
time.sleep(2)
#확대된 이미지의 정보는 img태그의 _image_source라는 class안에 담겨있다.
html_objects = browser.find_element_by_tag_name('img._image_source')
current_src = html_objects.get_attribute('src')
print("=============================================================")
print("현재 src :" +current_src)
print("이전 src :" +before_src)
if before_src == current_src:
continue
elif before_src != current_src:
t = urlopen(current_src).read()
if index < 40 :
filename = "Car_"+str(count)+".jpg"
with open(filename, "wb") as f:
f.write(t)
count += 1
before_src = current_src
current_src = ""
print("Img Save Success")
else:
browser.close()
break

위의 전체 썸네일이 포함된 영역은 위의 파란색으로 강조된 부분에 포함되어 있기 때문에 span태그(img_border 클래스)를 list형식으로 담은것이다.
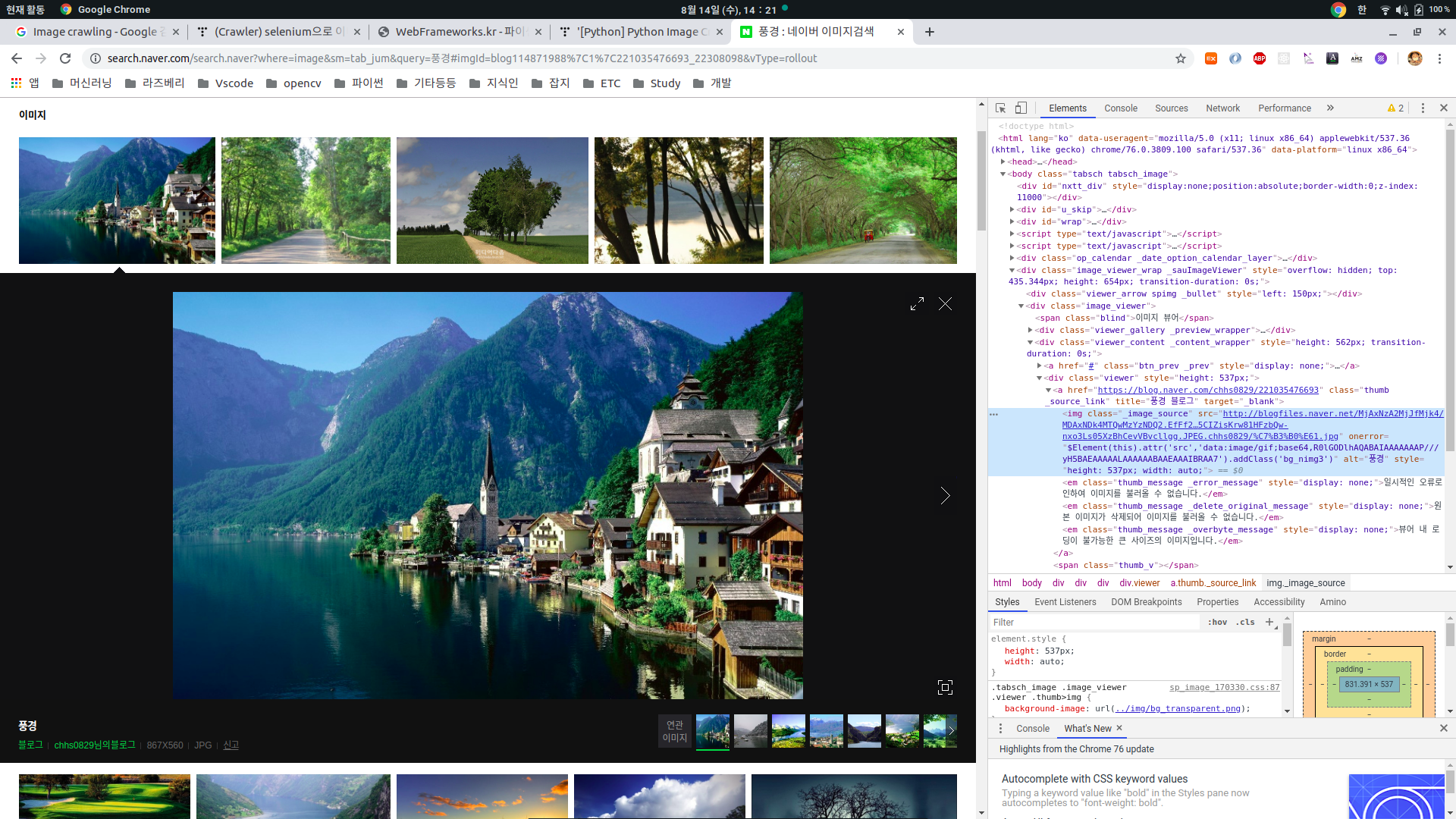

위와 같이 썸네일을 클릭시에는 html이 변경되기 때문에, 바뀐 html에서 img태그(_image_source)의 정보 중 src주소를 저장하여, 크롤링을 한다.
뭔가 좀 두서없긴한데.......
글을 읽고 피드백은 언제든지 환영입니다.....부족하거나 좀 채워야할 점이 있다면 언제든 답글달아주세요!!ㅎㅎ
'프로그래밍 > Python' 카테고리의 다른 글
| [TDD][Python] unittest - 예제로 익혀보기(1) (0) | 2022.03.16 |
|---|---|
| [TDD][Python] 단위 테스팅이란 (0) | 2022.03.16 |
| [Python] Python webCrawling+Ubuntu18.04 설정::우주를놀라게하자 (0) | 2019.08.09 |
| [Python] Ubuntu + Django를 활용하여 채팅 프로그램 만들기 2편 ::우주를놀라게하자 (0) | 2019.07.16 |
| [Python] Ubuntu + Django를 활용하여 채팅 프로그램 만들기 1편 ::우주를놀라게하자 (0) | 2019.07.15 |

